Introducción
En el análisis orientado a objetos encontramos que algunas entidades tienen un tipo de relación especial: herencia. A la hora de establecer estas relaciones se suele tener en cuenta aspectos tales como: árboles de jerarquías, especializaciones de entidades, tipo de dato y hasta la evaluación de usar "composición / agregación" en lugar de herencia (como lo sugieren algunos patrones GOF; ej.: Bridge, Visitor)
Sin embargo, un aspecto que suele quedar por fuera del análisis es cómo persistir una relación de herencia entre clases usando un modelo de tablas relacionales.
El objetivo de este artículo es analizar este aspecto y proponer soluciones concretas para aplicar en nuestros sistemas.
Sin embargo, un aspecto que suele quedar por fuera del análisis es cómo persistir una relación de herencia entre clases usando un modelo de tablas relacionales.
El objetivo de este artículo es analizar este aspecto y proponer soluciones concretas para aplicar en nuestros sistemas.
Relación entre análisis y programación orientada a objetos
En primer lugar es importante establecer una diferenciación entre el análisis orientado a objetos y la programación orientada a objetos. De esta manera podremos darnos cuenta que una actividad debería estar acompañada de la otra generalmente aunque esto no es un requisito excluyente.
El análisis orientado a objetos es una etapa donde no estamos construyendo un producto sino que estamos entendiendo su complejidad y características.
Esta actividad supone que un problema dado es entendido como un conjunto de entidades que tienen características, acciones y reacciones. Adicionalmente esto permite entender las relaciones que existen entre estas entidades.
De esta forma no interesa si la solución de software estará programada orientada a objetos o no, ya que el foco está puesto en entender y explicar el problema.
Este enfoque es válido, a mi juicio, para cualquier tipo de problema que analicemos dado que, como seres humanos, construimos nuestra realidad en base a conceptos descritos por un nuestro lenguaje. Y toda nuestra realidad se construye a partir de las relaciones que existen entre estos conceptos.
La programación orientada a objetos es una solución concreta basada en un paradigma que utiliza los mismos conceptos teóricos que el análisis orientado a objetos pero ello no significa que deba existir una correspondencia 1 a 1 entre el análisis y la solución. Es decir que las entidades que un analista funcional encontró para describir un problema no es obligatorio que sean las mismas a la hora de desarrollar la solución de software. En este sentido, dentro de la ingeniería de software, algunas técnicas de desarrollo proponen hacer un desarrollo dirigido por dominio (DDD) lo cual significa darle el máximo de protagonismo a las entidades del dominio del problema y hacer de ello la capa de software que dirige el resto de la arquitectura.
Herencia aplicada
Tanto desde el análisis como desde la programación, la herencia se utiliza para los mismos fines:
- Generar una jerarquía de entidades
- Crear especializaciones de entidades
- Reutilizar conceptos / código de programación
- Extender modelos
Si la respuesta es un SI entonces estamos en condiciones de aplicar el concepto de herencia. Pero si la respuesta es "puede ser", "depende" o cualquier otra que no sea un SI entonces hay que analizar con cuidado si estamos ante una relación de herencia o no.
La identidad de un objeto se define por combinación de sus características, su forma. Por esta razón, para responder a la pregunta anterior es necesario conocer la identidad de las dos entidades. Si me preguntan a mi si es lo mismo una Accion de Bolsa que un Bono de Canje....la respuesta es no sé!. Si me definen las características de ambos podré responder correctamente.
También es posible que la respuesta sea un SI pero al revisar las clases "hermanas" notemos algo extraño: que no parezca correcto que sean clases hermanas. En este caso lo que sucede es que una entidad no debe heredar directamente de otra sino que deben crearse otros eslabones en la jerarquía de clases.
Supongamos el siguiente caso: tengo una clase ControlVisual, de la cual hereda una clase Button; necesito agregar una clase TextBox y entonces pregunto: un TextBox es un ControlVisual?; al ser la respuesta un SI me debo preguntar también si es correcto que un TextBox esté a la par de un Button; si bien tiene características compartidas, cada uno podría tener una clase base distinta para formar, por ejemplo, una jerarquía como esta:
- ControlVisual >ControlPresionable>Button
- ControlVisual>ControlEditable>TextBox
Persistencia de la herencia
Es fundamental aclarar que lo que sigue solo se aplica para los casos de herencia donde la clase padre no es una clase abstracta. Si así lo fuera significaría que la entidad en sí no existe sino que actúa como molde o plantilla para otras entidades. Por esta razón las entidades abstractas no se persisten.En el modelo de base de datos relacionales, una tabla puede tener su propia identidad, la cual se expresa por medio de una clave primaria. Con esta solución es posible individualizar cada uno de los registros dentro de la tabla porque cada uno tiene una identidad distinta (no casualmente al campo clave primaria se lo suele denominar ID ).
La relación que existe entre el modelo relacional y el modelo de objetos se manifiesta de esta forma:
- Cada instancia de un objeto se representa en el modelo relacional con un registro de una tabla
- La forma de un objeto está determinada por su Clase y en el modelo relacional la forma de un registro está determinada por la tabla que lo contiene
- Si cada registro de una tabla tiene su propia identidad (ID) entonces el objeto en memoria tendrá un atributo que actuará de la misma forma.
Tomemos el siguiente ejemplo de herencia de clases:

Lo primero que hay que entender es que la relación de herencia no significa que una persona tiene un empleado o que un empleado tiene un vendedor. Lo que realmente significa es que un empleado ES UNA persona y un vendedor ES UN empleado y por lo tanto también una persona.
La identidad de la clase empleado ES la suma de todos sus atributos más los de la clase persona y lo mismo sucede con vendedor.
En términos de persistencia esto significa que un registro de la tabla empleados no tiene sentido si no existe el registro relacionado de la tabla personas. Es decir, no hay empleado si no hay persona.
En el modelo relacional para aplicar este concepto lo que debemos hacer es que la tabla empleados no tenga un ID propio, sino el mismo ID que personas, aplicando además una restricción de borrado en cascada para mantener la integridad de los datos. Y en el caso de la tabla vendedores se debería aplicar la misma inteligencia. La cardinalidad de las relaciones que reflejan herencia sería de 1 a 1.

El problema de la impedancia
Si necesito representar un conjunto de empleados en memoria podría armar una lista de empleados de esta forma:List<
Cada elemento de la colección Empleados tiene los atributos de Persona y Empleado, por lo tanto para llenar la colección con los datos del modelo relacional tendría un problema de impedancia.
Esto se debe a que ,desde el punto de vista de los objetos, tengo los atributos de dos entidades reunidos en una (porque represento solo herencia de un nivel), pero desde el punto de vista relacional tengo dos tablas distintas unidas por una clave primaria en común. Es decir que si pensaba que podía mapear una Clase con una Tabla aquí me doy cuenta que no. En este caso necesito dos tablas para mapear una Clase.
Para cargar con valores de la base de datos una instancia de Empleado tendría que ejecutar consultas en múltiples tablas (dos en este caso). Si quiero automatizar el proceso de carga de datos en objetos debería conocer de alguna forma que este objeto se divide en dos tablas, y esa información debería estar en alguna parte del objeto.
Para solucionar este problema y asociar un objeto con un solo elemento de la base de datos sería conveniente crear una VISTA justo después de crear las dos tabla en que se divide en empleado, la cual traiga todos los atributos de ambas tablas y se llame Empleados. Para ello la segunda tabla que antes habíamos pensado llamarla así ahora debería llamarse por ejemplo Empleados_TBL.
Y para el caso de la Clase Vendedor habría que hacer lo mismo: es decir, renombrar la tabla como Vendedores_TBL y crear una vista llamada Vendedores. Pero en este caso, como se trata de una relación de tres niveles de herencia habría que hacer un JOIN entre Vendedores_TBL y Empleados (la vista) de manera que la unión con Personas sea implícita.
Empleados:
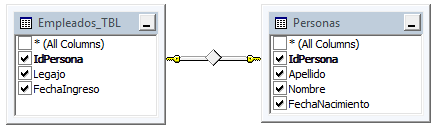
La vista tendría tanto el IdPersona de la tabla Personas como el IdPersona de la tabla Empleados, solo que este último habría que ponerle un alias, por ejemplo, IdEmpleados (lo importante es que la forma de asignar el alias sea una regla constante en todos los casos: "Id" + Nombre de la tabla
Vendedores:

Aquí se aplica la misma lógica que en el caso anterior, es decir, incorporo el IdPersona de Empleados y Vendedores pero este último lo llamo IdVendedores.
De esta forma ya logramos tener una correspondencia de 1 a 1 para las relaciones de herencia, donde una Clase se corresponde con una Tabla o con una Vista que toma información de varias tablas.
Como ya es sabido, a la hora de realizar un Insert es perfectamente realizable sobre la una vista si es que tiene todo los campos necesarios.
El problema de la cardinalidad
¿Que sucedería si en realidad lo que necesito persistir es que una persona puede tener múltiples empleos a lo largo del tiempo?. Es decir, quiero que un registro de la tabla personas pueda estar relacionado con varios registros de la tabla empleados (ej.: una persona que en 10 años ingresó dos veces a la empresa como empleado).
Desde el modelo relacional lo que necesitaría es que la tabla empleados tenga su propio ID y mantener un ID externo que apunte a la tabla personas, aplicando así la relación de uno a muchos mirando desde personas a empleados.

Pero en el mundo orientado a objetos esto genera un cambio importante. El cambio es tan importante que en realidad un empleado YA NO ES una persona sino que una persona pasa a tener N empleados asociados.
Es decir, debería dejar de tener la relación de herencia entre ambos y pasaría a tener una relación de agregación, donde en Persona tendría un atributo de tipo lista de empleado (List




